
引言
利用人眼的感知能力,对数据进行交互的可视表达,以增强认知的技术,称为可视化。 —唐泽圣
人类的生物特性:
- 人眼是一个高带宽的巨量视觉信息输入并行处理器,最高带宽为每秒100MB。
- 视觉是获取信息的最重要通道,超过50%的人脑功能用于视觉的感知。
- 在人类获得的外界信息中,80%来自视觉。
视觉的生物特性
视觉的生理机制包括折光机制、感知机制、传导机制和中枢机制。
视觉的中枢机制:
视觉的直接投射区为大脑枕叶的纹状区(布莱德曼第17区),这是实现对视觉信号初步分析的区域。与第17区临近的另一些脑区,负责进一步加工视觉的信号,产生更复杂、更精细的视觉,如认识形状、分辨方向等。
视觉的基本现象(简述):
光线的基本特性有:强度、空间分布、波长和持续时间。我们的视觉系统在反应光的这些特性时,产生了一系列视觉现象。
- 明度:眼睛对光源和物体表面的敏感程度的感受,主要是由光线强度决定的一种视觉经验。
- 颜色:光波作用于人眼所引起的另一种视觉经验。颜色具有三个基本特性,即色调、明度和饱和度。
视觉中的空间因素:
- 视觉对比:由光刺激在空间上的不同分布引起的视觉经验,可分成明暗对比与颜色对比两种。
- 边界突出与马赫带:马赫带是指人们在明暗变化的边界上,常常在亮区看到一条更亮的光带,而 在暗区看到一条更暗的线条,如图所示。
我们可以用侧抑制来解释马赫带的产生。 - 视敏度:视觉系统分辨最小物体或物体细节的能力。医学上称之为视力。

视觉中的时间因素:
- 视觉适应:由于刺激物的持续作用而引起的感受性的变化。在视觉范围内,可区分为暗适应和明 适应。
- 后像:刺激物对感受器的作用停止以后,感觉现象并没有立即消失,它能保留一个短暂时间,这 种现象叫后像。后像分两种:正后像和负后像。
- 闪光融合:当我们看一个间歇频率较低的闪光时,得到的是明暗交替的闪烁感觉,当连续的闪光 间歇频率增加,人们看到的将不再是闪烁的光,而是稳定的连续光,这种现象叫闪光融合。
- 视觉掩蔽:在某种时间条件下,当一个闪光出现在另一个闪光之后,这个闪光能影响到对前一个 闪光的觉察,这种效应称为视觉掩蔽。
视觉感知和认知
在可视化与可视化分析过程中,用户是所有行为的主体:通过视觉感知器官获取可视信息、编码并形成认知,在交互分析过程中获取解决问题的方法。
视觉感知和认知的定义:
- 感知是客观事物通过感觉器官在人脑中的直接反映。人类感觉器官包括眼、鼻、耳,以及遍布身体各处的神经末梢等,对应的感知能力分别称为视觉、嗅觉、听觉和触觉等。
- 认知指在认识活动的过程中,个体对感觉信号接收、检测、转换、简约、合成、编码、储存、提取、重建、 概念形成、判断和问题解决的信息加工处理过程。
格式塔学派:
格式塔学派主张人脑的运作原理属于整体论,“整体不同于其部件的总和”。例如,我们对一朵花的感知,并非纯粹单单从对花的形状、颜色、大小等感官资讯而来,还包括我们对花过去的经验和印象,加起来才是我们对一朵花的感知。
格式塔体系的关键特征是整体性、具体化、组织性和恒常性。
格式塔学派最基本的规则是蕴涵律:闭合律、相似律、接近律、连续律。
视觉编码
用户对可视化的感知 和理解通过人的视觉通道完成。在可视化设计中,对数据进行可视化(视觉 )元素映射时,需要遵循符合人类视觉感知的基本编码原则,这些原则跟数据类型紧密相关。在通常情况下,如果违背了这些基本原则,将阻碍或误导用户对数据的理解。
什么是视觉编码?
视觉编码描述的是将数据映射到最终可视化结果上的过程。
什么是视觉通道?
图形符号→信息→视觉系统
图形符号与信息的对应关系:
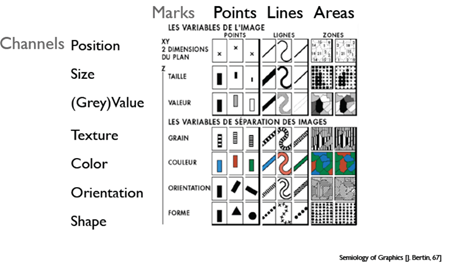
- 位置变量:一般指二维坐标。
- 视网膜变量:颜色(亮度,饱和度,色调,配色方案)、尺寸、斜度和角度、形状、纹理、动画,透明度,模糊/聚焦等。
视觉通道的性质:
- 定性性质(分类性质):适用于类别型数据。比如形状或颜色,这两个视觉通道,非常容易被人眼识别。
- 定量性质(定序性质):适用于有序型和数值型数据。比如长度、大小,特别适合于编码数值的大小。
- 分组性质:具有相同视觉通道的数据,人眼也能很快识别出来,将其归为一组。
可视化中数据可分为三类:类别型、有序型、数值型。
视觉通道与数据类型的对应关系如图所示。

视觉编码设计的原则:
- 表达性、一致性:可视化的结果应该充分表达了数据想要表达的信息,且没有多余。
- 有效性、理解性:可视化之后比前一种数据表达方案更加有效,更加容易让人理解。
视觉编码针对不同数据类型的优先级:
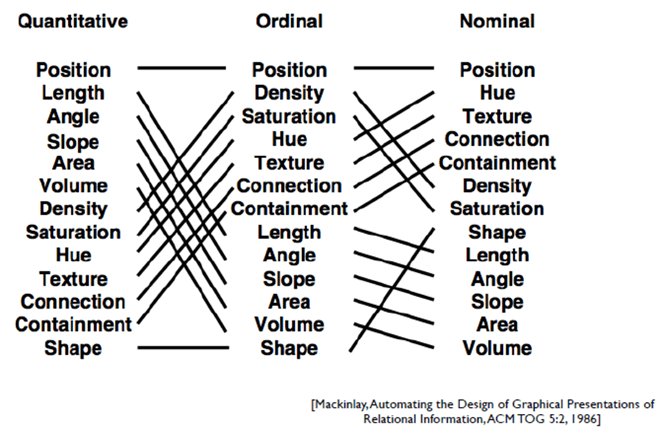
设计可视化编码除了视觉通道还需要考虑:
- 色彩搭配
- 交互
- 美学因素
- 信息密度
- 直观映射、隐喻
数据可视化的基本概念
什么是可视化
可视化将不可见或难以直接显示的数据转化为可感知的图形、符号、颜色、纹理等,增强数据识别效率,传递有效信息。
数据可视化大致可分为信息可视化、科学可视化和可视化分析。
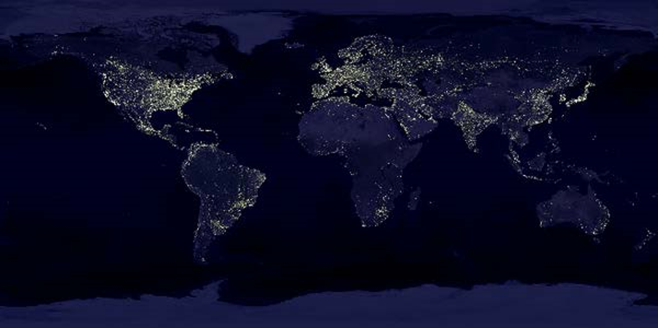
世界夜晚灯光图
可视化的分类
信息可视化

科学可视化

Visualizing (scalar) data with isosurfaces
http://www.sci.utah.edu/~cscheid/fal05/scivis/project3/
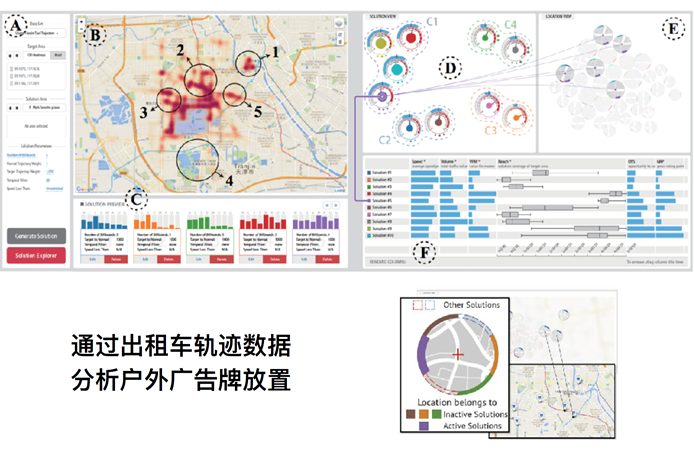
可视化分析
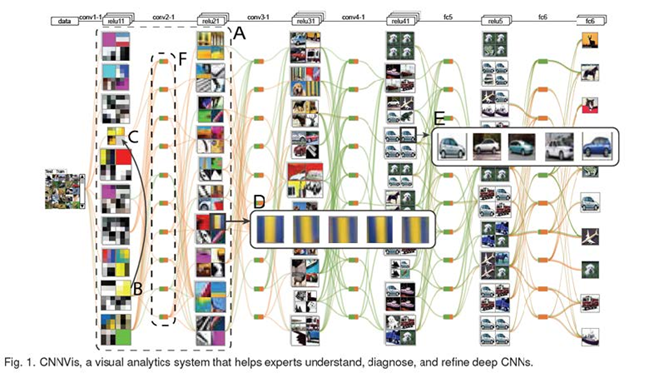
帮助研究者更好的理解、判断和调整深度卷积神经网络。
为什么要可视化?
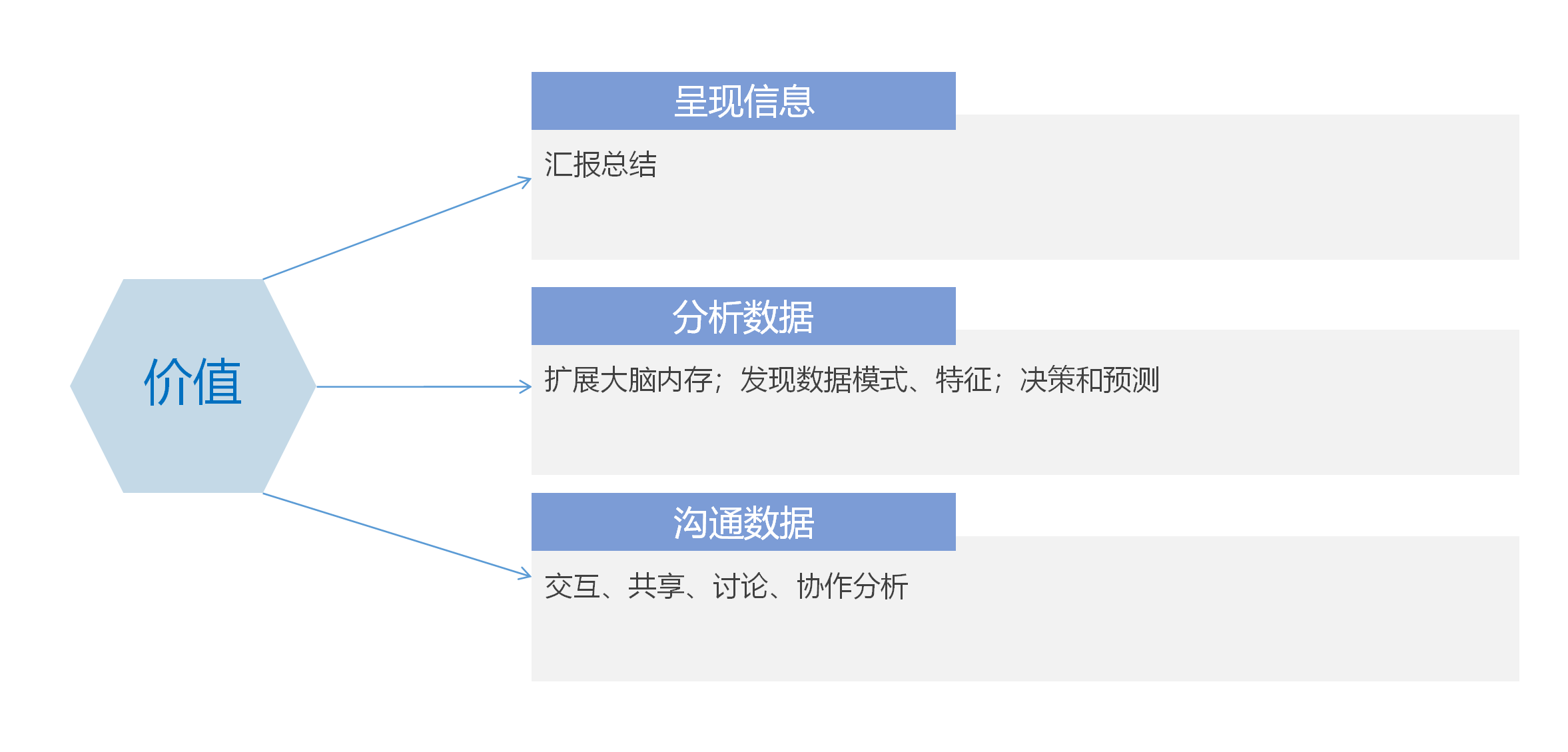
可视化的作用
- 记录信息
- 发现模式
- 分析与推理
- 交流与传播


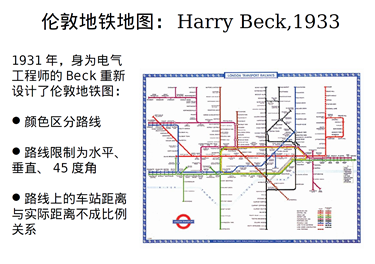
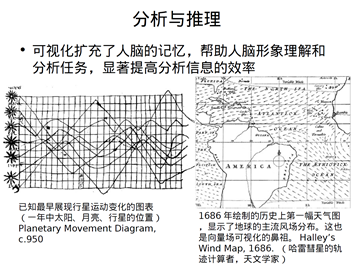
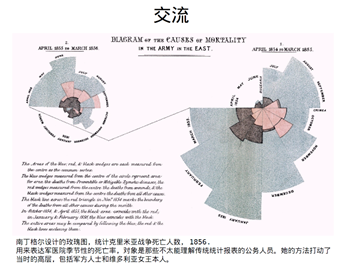
综合上述可视化的作用可总结以下几点:
- 协助思考
- 使用感知代替认知
- 作为大量工作记忆的外界辅助
- 增强认知能力
为什么?
- 信息科学领域面临的一个巨大挑战是数据爆炸。
- 互联网使得信息采集与传播的速度和规模达到空前的水平,实现了全球的信息共享与交互。
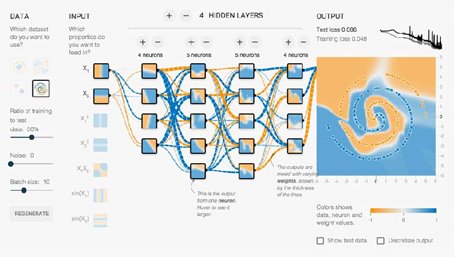
可视化帮助机器学习

发展历史
1700年之前:伴随着物理测量的图表萌芽
– 17世纪最重要的科学进展是对物理基本量的测量设备与理论的完善。
– 制图学、基于真实测量数据的可视化方法迅速成长。
1700-1987:统计可视化
– 概率统计的发展与图形抽象。
– 信息可视化发展成为一门学科。
1987至今:科学计算可视化
– 1986年,美国国家科学基金会主办了一次名为“图形学、图像处理及工作站专题讨论”的研讨会,将计算机图形学和图像方法应用于计算科学的学科称为“科学计算之中的可视化”(Visualization in Scientific
Computing)。
– 1987年,美国国家科学基金会召开了首次有关科学可视化的会议,正式命名并定义了科学可视化(Scientific Visualization)。
– 1990年,举办了首届IEEE Visualization Conference。
1989至今:信息可视化
– 数字化的非几何的抽象数据大量涌现,如金融交易、社交网络、文本数据等,促生了多维、时变、非结构化信息的可视化需求。
– 基于统计图形学的,针对抽象信息的视觉表达手段不断发展。
– 1989年,Card、Mackinlay和Robertson等人采用“ information visualization”命名学科,其研究思想是对统计图形学的升华。
2004至今:可视分析学
– 原有的可视化技术难以应对海量、高维、多源和动态数据的分析挑战,需要综合可视化、图形学、数据挖掘理论与方法,研究新的理论模型、新的可视化方法和新的用户交互手段,辅助用户从大尺度、复杂、矛盾、不完整的数据中快速挖掘有用的信息,以便做出有效决策。这门新兴的学科称为可视分析学。
– 2006年,美国国家科学基金会发布专题报告描述大规模数据可视化所面临的挑战。
– 同年,IEEE开设了国际会议IEEE VAST。
数据模型
数据:数据是一组关于一个或多个人或对象的定性或定量变量。
数据模型:一组数字或符号的组合,它包含数据的定义、类型等,可以进行各类数学操作等。
数据的分类:
- 类别型:数据用于区分事物。例如,人可以分为男女,水果能分为苹果香蕉等。
- 有序型:用来表示对象间的顺序关系。例如,我们的身高可以从矮到高,学生的成绩可以从低到高排列等。
- 区间型:用于对象间的定量比较。例如,身高 160cm 与身高 170cm 相差 10cm,而 170cm 与 180cm 也相差 10cm,它们俩的差值是相等的。由此可见,区间型数据基于任意的起始点,所以它只能衡量对象间的相对差别。
- 比值型:用于比较数值间的比例关系。例如,体重 80kg 是体重 40kg 的两倍。
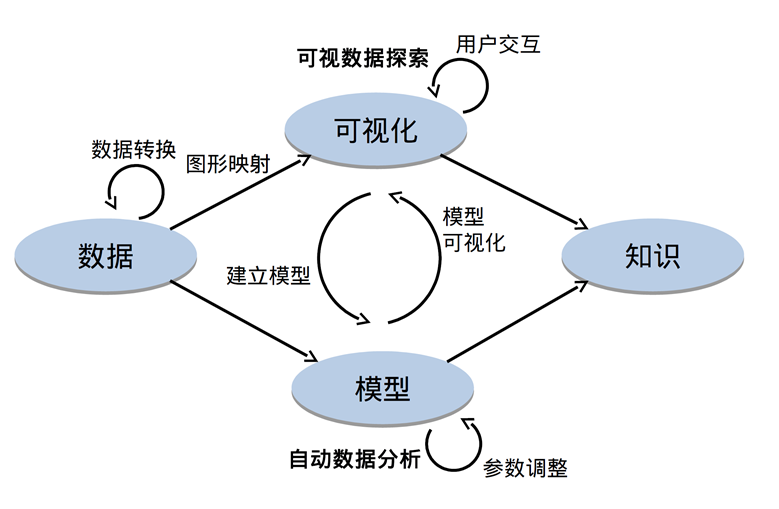
数据可视化的基本流程
通用可视化流程
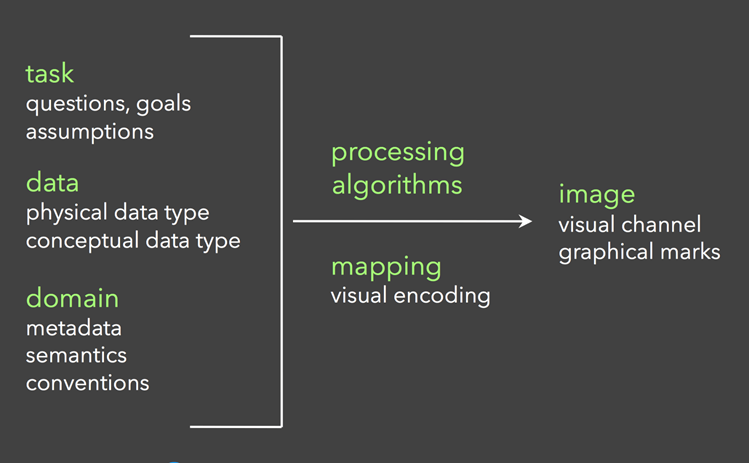
分析→处理→生成
- 分析分为三部分:任务、数据、领域。
- 任务:分析可视化的目的和目标是什么,遇到了哪些问题,要展示什么信息,需要得出什么结论,验证什么假说等。不同的数据展示方式的侧重点不同。明确以上问题,确定过滤的目标数据,以什么算法处理数据,用什么视觉通道编码等。
- 数据:分析数据的数据类型,数据结构,纬度等。
- 领域:针对不同的领域进行相应的数据分析。
- 处理分为两部分:数据处理、视觉编码处理。
- 数据处理:在可视化前对数据进行数据清洗、数据规范、数据分析。数据清洗和规范的目的是把脏数据、敏感数据等过滤,剔除和目标无关的冗余数据,调整数据结构到系统可以接受的方式。
- 视觉编码处理:如何使用位置、尺寸、灰度值、纹理、色彩、方向、形状等视觉通道,以映射要展示的每个数据维度。
- 生成阶段将上述的分析和设计付诸实践,不断调整需求,不断迭代,最终输出需要的结果。
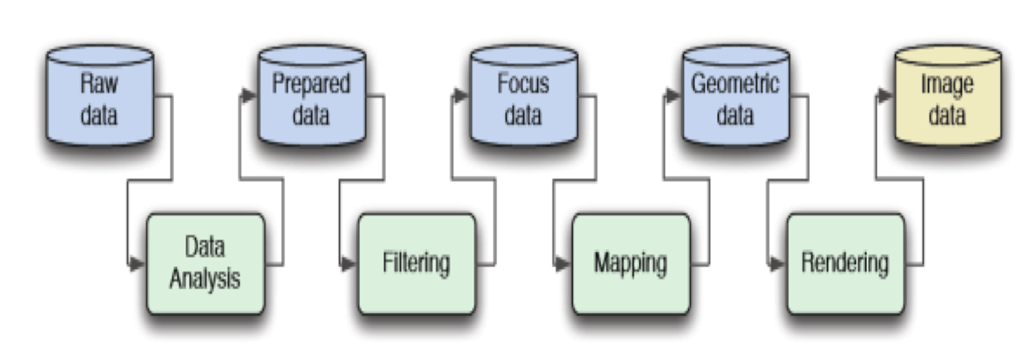
线性流程
1990 年 Robert B. Haber 和 David A. McNabb 提出的数据可视化流程已经非常先进,整个流程是线性的。它把数据分成五大阶段,分别要经历四个流程,每个过程的输入是上一个过程的输出。
嵌套模型
嵌套模型的上半部分为分析、处理两步。下半部分是对可视化结果的验证。本质上是一个验证加迭代的过程。

循环模型
循环模型的以下图片都是把线性模型首尾连起来。

目前应用最广的模型
对比之前的线性模型,其实也很类似,不过其在最后加入了用户交互的部分,且让每个步骤都变成了循环的。这是目前应用最广的可视化流程模型,后继几乎所有著名的信息可视化系统和工具都支持、兼容这个模型。
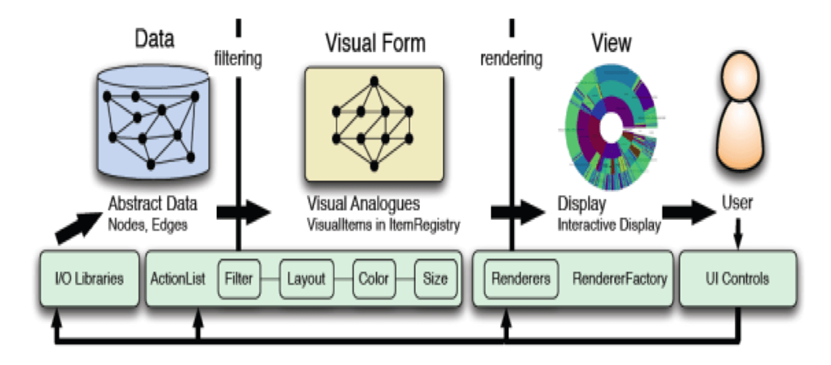
数据可视化的手段
工具

图表
数据轨迹:
数据轨迹是一种标准的单变量数据呈现方法:x轴显示自变量;y轴显示因变量。数据轨迹可直观地呈现数据分布、离群值、均值的偏移等。如图所示。

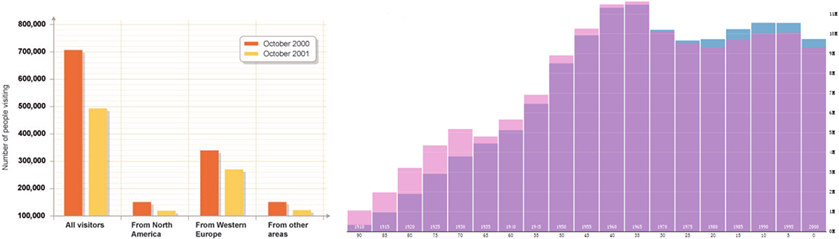
柱状图:
柱状图采用长方形的形状和颜色编码数据的属性。柱状图的每根直柱内部也可用像素图方式编码,也称为堆叠图。如图所示。
直方图:
直方图是对数据集的某个数据属性的频率统计。对于单变量数据, 其取范围映射到横轴, 并分割为多个子区间。 每个子区间用一个直立的长方块表示, 高度正比于属于该属性值子区间的数据点的个数。

散点图:
散点图是表示二维数据的标准方法。在散点图中,所有数据以点的形式出现在笛卡尔坐标系中,每个点所对应的横纵坐标即代表该数据在坐标轴所表示维度上的属性值大小。
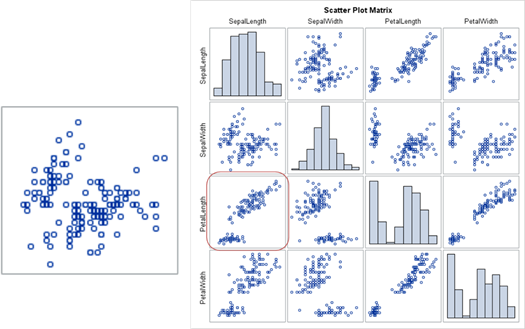
散点图矩阵:
散点图矩阵是散点图的高维扩展,用来展现高维(大于二维)数据属性分布。可以通过采用尺寸、形状和颜色等来编码数据点的其他信息。对不同属性进行两两组合,生成一组散点图,来紧凑地表达属性对之间的关系。
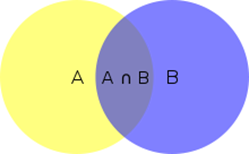
文氏图:
在文氏图法中,如果有论域,则以一个矩形框(的内部区域)表示论域;各个集合(或类)就以圆/椭圆(的内部区域)来表示。两个圆/椭圆相交,其相交部分表示两个集合(或类)的公共元素,两个圆/椭圆不相交(相离或相切,而实际上在文氏图中相切是没有什么意义的,因为文氏图是以图形的内部区域来表示的)则说明这两个集合(或类)没有公共元素。
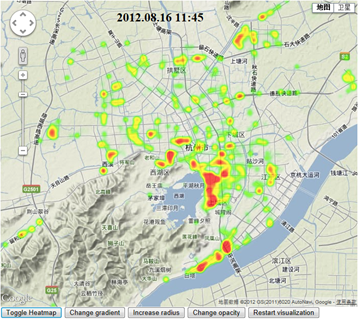
热力图:
热力图使用颜色来表达位置相关的二维数值数据大小。 这些数据常以矩阵或方格形式一整齐排列,或在地图上按一定的位置关系排列,每个数据点的颜色编码数值大小。
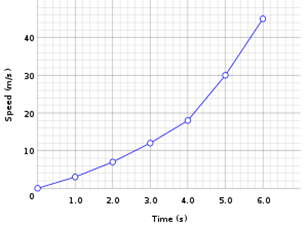
折线图:
折线图以X轴为基础,将X轴上相邻的资料点之间用直线连接。折线图常用来观察资料在一段时间之内的变化(时间序列),因此其X轴为时间,这种折线图又称为趋势图。
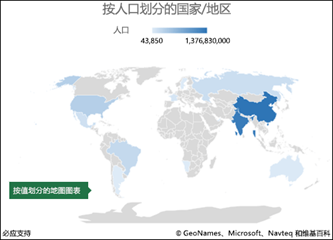
地理图:
一切和空间属性有关的分析都可以用到地理图。比如各地区销量,或者某商业区域店铺密集度等。地理图一定需要用到坐标维度。可以是经纬度、也可以是地域名称(上海市、北京市)。坐标粒度即能细到具体某条街道,也能宽到世界各国范围。
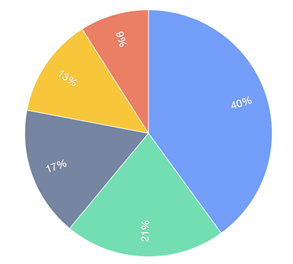
饼图:
一个划分为几个扇形的圆形统计图表,用于描述量、频率或百分比之间的相对关系。在饼图中,每个扇区的弧长大小为其所表示的数量的比例。
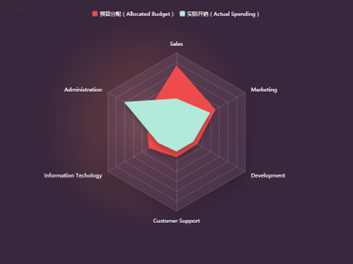
雷达图:
又被叫做蜘蛛网图,适用于显示三个或更多的维度的变量。雷达图是以在同一点开始的轴上显示的三个或更多个变量的二维图表的形式来显示多元数据的方法,其中轴的相对位置和角度通常是无意义的。
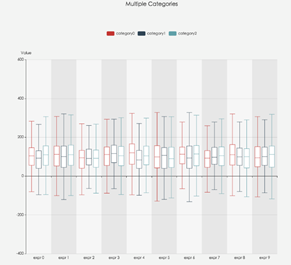
箱线图:
利用数据中的五个统计量:最小值、第一四分位数、中位数、第三四分位数与最大值来描述数据的一种方法,它也可以粗略地看出数据是否具有有对称性,分布的分散程度等信息,特别可以用于对几个样本的比较。
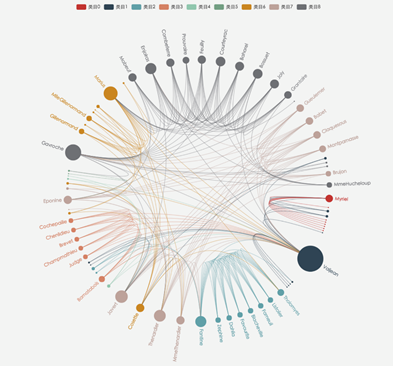
关系图:
展现事物相关性和关联性的图表,比如社交关系链、品牌传播、或者某种信息的流动。
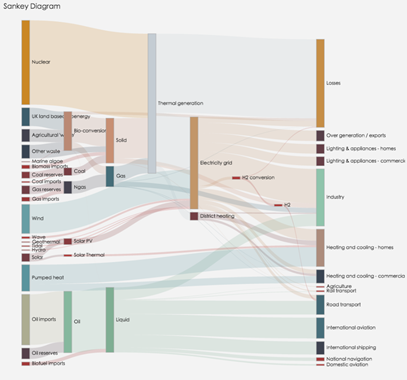
桑基图:
桑基图是一种数据流图,展示了数据是如何从左到右流向最后的节点,每条边代表一条数据流,宽度代表数据流的大小。桑基图常用于流量分析。
矩形树图:
矩形树图适合展现具有层级关系的数据,能够直观体现同级之间的比较。一个Tree状结构转化为平面空间矩形的状态。

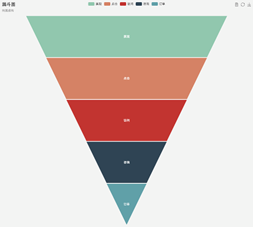
漏斗图:
漏斗图适用于业务流程比较规范、周期长、环节多的单流程单向分析,通过漏斗各环节业务数据的比较能够直观地发现和说明问题所在的环节,进而做出决策。漏斗图用梯形面积表示某个环节业务量与上一个环节之间的差异。漏斗图从上到下,有逻辑上的顺序关系,表现了随着业务流程的推进业务目标完成的情况。
大家好,今天我要分享的内容是数据可视化。
我们从四个部分来介绍,首先是引言,期中包括一些背景和预备知识。接下来是基本概念,流程,以及可视化手段。
我们先来看一句大佬说的话“利用人眼的感知能力,对数据进行交互的可视表达,以增强认知的技术,
称为可视化。”大致知道可视化是个什么,它可以帮助我们更好的认知数据,从而做出相应的决策和判断。
下面是人类的生物特性,这三条总结下就是人眼很厉害,大脑也很厉害。我们借助视觉,加上可视化的手段,可以认知到更广范围的信息。
这里介绍视觉的生理机制,这就是在讲我们的硬件。我们得先了解我们拥有的硬件特征,才能更好的发挥运用它们。
包括(机制),中枢机制可以产生更复杂,更精细的视觉...。
其次是视觉的基本现象,就是我们看到的东西用一些指标来量化,像明度...颜色,由光的波长决定。
还有视觉的空间因素,马赫带的产生,以及视觉中的时间因素。这些可以帮助我们更好的了解人眼的硬件属性,辅助我们的可视化项目。
上面是视觉,人眼看到后,信号传递给大脑,产生感知和认知。感知相当于直接的输入信号,认知相当于对这些输入信号进行进一步的加工处理。
下面是一个比较主流的理论。感知包括我们过去的经验和印象。
视觉编码,视觉编码描述的是将数据映射到最终可视化结果上的过程。
这里的可视化结果可能是图片,也可能是一张网页等等。
编码二字,如果说编是指设计、映射的过程,那么码呢?码其实指的是一些图形符号。
右边这张图就是,视觉编码中常用的视觉通道
类别型nominal、有序型ordinal、数值型quantitative。
第二部分我们来介绍数据可视化的基本概念,正式入门。
数据可视化是什么?把数据用图表展现出来?把数据变得酷炫吗?当然也对。同时也其他作用。
看这里的定义,(...)像下面的世界夜晚灯光图,看这里非洲看起来就暗淡好多,当然肯定也有其他因素。
我们通过这样的形式,大脑很容易就能感知到信息。
这里是可视化的分类,()
信息图的制作流程,通过这张图就可以把它完整的工作流直观的展现出来。
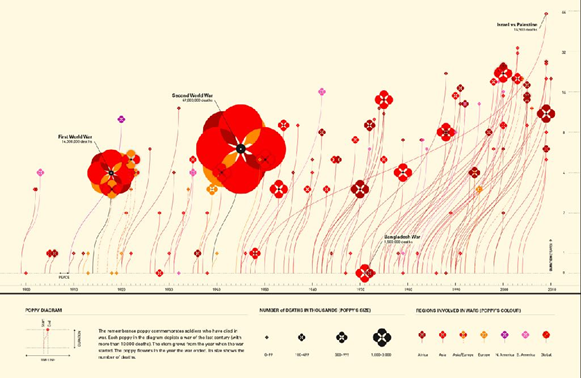
红色的是罂粟花,越大死亡人数越多,横轴-时间轴 纵轴-战争持续的时间 起始点-开始 终止点-结束
科学可视化,左边是通过解刨,得到的数据,分层构建出人体的模型,
右边 风向,温度的可视化。
可视化分析,通过收集到的出租车轨迹的数据,分析得出户外广告牌防止的最优位置,达到最佳的广告投放目的。
机器学习 是黑盒,可视化后方便更好理解,优化模型
时空数据:大气流,大气场,向量,张量
地理数据:和地图有关
时序数据:和时间变化有关
高维数据:数据纬度很多。
层次数据:树形结构
网络数据:节点,边
媒体数据:和社交媒体相关的数据
科学:左上海洋洋流,右上左下热带风暴,右下地震的数据
深度学习,黑盒子,不知道每层网络做了什么,可视化帮助我们展示每一层神经元是什么样子
,更好的调整神经元的分布,网络层的参数。
可视化流程
首先是分析可视化任务,目标是什么,想从可视化中得到什么。
然后是数据类型,图结构,树结构,少量还是海量,高维还是低维
第三个,我们面向的领域是什么,领导,开发者还是什么。
然后把垃圾数据,敏感数据过滤掉。最后映射到一些视觉元素上完成可视化设计。
类别型:数据用于区分事物。例如,人可以分为男女,水果能分为苹果香蕉等。
有序型:用来表示对象间的顺序关系。例如,我们的身高可以从矮到高,学生的成绩可以从低到高排列等。
区间型:用于对象间的定量比较。例如,身高 160cm 与身高 170cm 相差 10cm,而 170cm 与 180cm 也相差 10cm,它们俩的差值是相等的。由此可见,区间型数据基于任意的起始点,所以它只能衡量对象间的相对差别。
比值型:用于比较数值间的比例关系。例如,体重 80kg 是体重 40kg 的两倍。
南丁格尔,世界上第一名真正的护士,5.12国际护士节设立在她的生日。
一个圆周分为12个部分,一个扇形代表一个月,每个扇形有多个色块。
浅色色块士兵在战争中伤病死亡,深色是直接死亡。由于医疗水平不足或救治不及时死亡的人数
比直接死亡的多的多。打动很多人,使得医事改良得到支持。
参考文献及链接:
- 陈为,沈则潜,陶煜波. 数据可视化. 电子工业出版社,2019年
- 彭聃龄. 普通心理学. 北京师范大学出版社,2012年
- https://antv-2018.alipay.com/zh-cn/vis/chart/index.html
- http://www.cad.zju.edu.cn/home/vagblog/?page_id=1302
- https://img.xiaoqiqiao.com/syllabus/5-7/数据可视化简介1578645326.pdf
- https://raw.githubusercontent.com/NodeParty-China/Node-Party/master/2017-08-19/visualization_node_party.pdf
- https://geekplux.com/
版权属于:moluuser
本文链接:https://moluuser.com/archives/79/
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。

